अक्षरांचे संख्याशास्त्र आणि मराठीची तदानुषंगिक थट्टा
अक्षरांचे संख्याशास्त्र आणि मराठीची तदानुषंगिक थट्टा
लेखक - जयदीप चिपलकट्टी
इंग्रजी लिखाणामध्ये e ह्या अक्षराचा वापर सर्वात जास्त होतो, हा शोध इतिहासात अनेकदा लागलेला आहे. अार्थर कॉनन डॉईलच्या 'The Adventure of the Dancing Men' या गोष्टीतून मला तो ठाऊक झाला. शिकागोमधल्या एक गुन्हेगारी टोळीच्या सदस्यांनी आपापसांत वापरण्यासाठी एक सांकेतिक लिपी तयार केलेली होती. वेगवेगळ्या अक्षरांसाठी वेगवेगळ्या आविर्भावांत नाचणाऱ्या माणसांची चित्रं, असा तक्ता तयार करून ती बनवलेली होती. उदाहरणार्थ, e ह्या अक्षरासाठी असा माणूस: 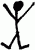
किंवा r साठी असा: 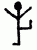
गोष्टीची नायिका एल्सी पॅट्रिक अमेरिकेतल्या तिच्या गतायुष्यात ह्या टोळीशी संबंधित होती, पण ते आता मागे सोडून देऊन इंग्लंडला येऊन ती लग्न करून राहिलेली होती. याच टोळीतल्या एब स्लेनी नावाच्या तिच्या वैफल्यग्रस्त प्रियकराला हे आवडलं नव्हतं. तिच्या मागोमाग तो इंग्लंडला आला, आणि ही लिपी वापरून तिला चिठ्ठ्या पाठवू लागला. हा प्रकार एल्सीच्या नवऱ्याला गूढाचा आणि धोक्याचा वाटल्यामुळे त्याने शेरलॉक्स होम्सची मदत घेतली. चिठ्ठ्यांचा अभ्यास करून होम्सने तर्क असा केला की त्यामध्ये जास्तीतजास्त वेळा येणारं चिन्ह e साठी असावं. एक अक्षर सापडल्यानंतर त्याच्या आधारे दुसरं, असं करत त्याने बाकीची चिन्हं शोधून काढली.
दरम्यान एके रात्री स्लेनी आणि एल्सीचा नवरा यांच्यात बाचाबाची होऊन गोळीबार झाला, नवरा ठार झाला आणि मध्ये सापडलेल्या एल्सीला मोठी जखम झाली. स्लेनी पळाला. होम्स घटनास्थळी गेला, त्याच लिपीमध्ये चिठ्ठी पाठवून त्याने स्लेनीला बोलावून घेतलं आणि रीतसर अटक केली. आपल्या टोळीबाहेरच्या कुणालाही ही लिपी माहित नसणार अशी खात्री असल्यामुळे त्याला संशय आला नव्हता. गोष्ट लक्षात राहण्यासारखी आहे. होम्सचा सुरवातीचा तर्क फसू नये म्हणून नायिकेचं नाव डॉईलने विचारपूर्वक Elsie असं ठेवलेलं आहे. ते Amanda किंवा Ursula ठेवणं हा खोडसाळपणा झाला असता.
मराठी लिखाणात मात्र सर्वांत जास्त वेळा येणारं अक्षर कोणतं हे मला ठाऊक नव्हतं, तेव्हा स्टॅटिस्टिकल अनॅलिसिस करून ते शोधून काढण्याचा जो प्रयत्न मी केला त्याचा हा वृत्तान्त आहे. (याच विषयावर मी 'ऐअ' मध्ये दोनेक वर्षांपूर्वी छोटासा लेख लिहिला होता, पण त्यानंतर हे काम आणखी थोडं पुढे नेलं आहे.)
इंटरनेटवरून मी मराठी लिखाणाची एकूण साठ सॅँपल्स गोळा केली. यामध्ये ऐअ, उपक्रम, मिसळपाव अशा साईट्सवरचे वेगवेगळ्या विषयांवरचे लेख आहेत, काही लेख ब्लॉग्सवरून उचललेले आहेत, तर काही वर्तमानपत्रांतली संपादकीयं आहेत (सकाळ, लोकसत्ता, दिव्य मराठी इत्यादि ठिकाणची). इथे उठबस असणाऱ्या अदिती, अरविंद कोल्हटकर, कविता महाजन, धनंजय, राजेश घासकडवी, रोचना अशा काही मंडळींचे लेख यांत आहेत. ही सॅँपल्स गोळा करताना काही पथ्यं मी पाळली: एका लेखकाचे दोनपेक्षा जास्त लेख घ्यायचे नाहीत, स्वत:चा एकही लेख घ्यायचा नाही, आणि पाचशे शब्दांपेक्षा लहान सॅँपल निवडायचं नाही. (तुलनेसाठी सांगायचं तर लोकसत्तेतलं संपादकीय अंदाजे नऊशे शब्दांचं असतं.) प्रत्येक लेखातले शब्द वेगळे करून, शब्दांतली अक्षरं वेगळी करून, क-ख-ग-घ पासून श-ष-स-ह-ळ पर्यंत कोणतं व्यंजन किती वेळा येतं, आणि कोणता स्वर किती वेळा येतो इत्यादीची मोजदाद करण्यासाठी मी एक कंप्यूटर प्रोग्रॅम लिहिला. (युनिकोड म्हणजे काय हे माहित असणाऱ्यांना हा प्रोग्रॅम कसा काम करतो याची सहज कल्पना करता येईल, पण इथे तो तपशील महत्त्वाचा नाही.)
डेटा मिळाल्यानंतर त्यातून स्पष्ट निष्कर्ष निघाला तो असा की मराठी लिखाणात 'त' हे व्यंजन सर्वांत जास्त प्रचलित आहे. दर शंभर अक्षरांमागे ते सरासरी अकरा वेळा येतं, इतकंच नव्हे तर कुठल्याही प्रकारचं लिखाण असलं तरी हे प्रमाण फारसं इकडेतिकडे होत नाही. म्हणजे समजा एका लेखामध्ये एकूण अ इतकी अक्षरं आहेत, आणि त्यामध्ये त इतक्या वेळा 'त' येतो. जर त/अ हे गुणोत्तर काढलं तर ते बहुतेक वेळा अकरा शतांशाच्या अासपास घोटाळतं. उदाहरणार्थ, सॅँपलमधले हे दोन लेख पाहा:
१. तीन म्हाताऱ्या, लेखिका: शहराजाद. (ऐअ दिवाळी अंक, २०१३)
२. बाळूगुप्ते, लेखक: राजेश घासकडवी. (ऐअ दिवाळी अंक, २०१२)
पहिल्या लेखामध्ये एकूण ५६६९ अक्षरं आहेत, आणि ६१९ वेळा 'त' येतो, म्हणजे हे गुणोत्तर ६१९/५६६९ = १०.९१% इतकं आहे. दुसऱ्या लेखासाठी ते ११३९/१००६१=११.३२% इतकं आहे. याचा अर्थ असा की दोन्ही लेखांची प्रकृती वेगवेगळी असूनही आणि दर्जात तफावत असूनही ही गुणोत्तरं एकमेकांच्या जवळ आहेत.
अर्थात लिखाणाचा फार छोटा तुकडा घेतला (उदा. हायकू किंवा एडस् निर्मूलनाची जाहिरात वगैरे) तर हा अकरा टक्क्यांचा अंदाज चुकेल, पण बऱ्यापैकी मोठा तुकडा असेल तर तो बव्हंशी बरोबर येतो. एक मार्गदर्शनात्मक निष्कर्ष या शोधातून निघतो तो असा की 'The Adventure of the Dancing Men' चं मराठीकरण करायचं झाल्यास नायिकेचं नाव 'तिलोत्तमा' ठेवता येईल.
'त' ह्या व्यंजनामागोमाग 'र-य-क-ल-स' या व्यंजनांचा क्रम लागतो. त्यांची अंदाजी प्रमाणं अनुक्रमे ९%, ८%, ७%, ६%, ५% अशी आहेत, म्हणजेच उदाहरणार्थ दर शंभर अक्षरांमागे आठ वेळा 'य' येतो. इथे थोडा फरक आहे तो असा: सर्वसाधारणपणे कुठलाही मराठी लेख घेतला तर बहुतेक वेळा 'त' जिंकतो. तुमच्या डोळ्यांसमोरचा लेख याला अपवाद नाही. (माझ्या साठ सॅँपल्सपैकी ज्यांत 'त' पहिला आला नाही अशी फक्त सोळा सॅँपल्स निघाली, आणि तिथेदेखील तो दुसरातिसरा आलाच.) पण त्याच्या मागून येणाऱ्या व्यंजनांचा क्रम इतका काटेकोर नाही. म्हणजे 'र' सर्वसाधारणपणे 'य' च्या पुढे असतो खरा, पण हा क्रम कित्येकदा उलटा होतो. परीक्षेचा निकाल बघून आलेल्या आपल्या मित्रांना सी. डी. देशमुखांनी (की रँग्लर परांजप्यांनी?) विचारलेला 'दुसरं कोण आलं' हा सुप्रसिद्ध प्रश्न 'त' ही विचारू शकेल.
सरसकट सगळ्या व्यंजनांचा हिशेब काढला तर
ही दहा व्यंजनं मिळून लिखाणातला जवळजवळ सत्तर टक्के भाग खातात. विषमता खूप आहे.
व्यंजनांचा त्यांच्या वर्गांनुसार हिशेब केला (उदाहरणार्थ, 'क'-वर्ग म्हणजे 'क-ख-ग-घ-ङ') तरीसुद्धा ही विभागणी उंचसखल आहे असं दिसतं:
'क'-वर्ग: १२% 'च'-वर्ग: ९%, 'ट'-वर्ग: ८%, 'त'-वर्ग: २२%, 'प'-वर्ग: १३%
उरलेले ३६% 'य-र-ल-व-श-ष-स-ह-ळ' मधून येतात.
याच धर्तीवर स्वरांचाही हिशेब करता येतो. सर्वांत जास्त वेळा येणारा स्वर 'अ' असावा याचं विशेष आश्चर्य वाटू नये. एकूण ४२% टक्के अक्षरांत तो येतो. त्याच्या खालोखाल 'आ' हा स्वर २७% अक्षरांत येतो. त्यानंतर इ-ई मिळून ११% वेळा येतात. इथपर्यंतचा हिशेब ८०% झाला; उरलेली २०% अक्षरं उ-ऊ-ए-ऐ इत्यादि बाकीच्या स्वरांत वाटली जातात.
अक्षरांच्या एकूण संख्येमधलं 'त' चं प्रमाण ११% पासून फारसं चळत नाही असा जो दावा मी मघाशी केला, तोच वर दिलेल्या इतर व्यंजनांसाठी आणि स्वरांसाठी पुष्कळसा खरा आहे. उदाहरणार्थ, शहराजाद यांच्या लेखामध्ये 'आ' हा स्वर २८.१०% अक्षरांत येतो, तर घासकडवींच्या लेखामध्ये तो २७.०६% अक्षरांत येतो, म्हणजे मोठा फरक नाही. सर्वसाधारण नियम असा की एखादा स्वर किंवा व्यंजन खूपदा येत असेल तर त्याचं प्रमाण बऱ्यापैकी स्थिर असतं, पण तुरळकपणे येणाऱ्यांचं प्रमाण चांगलंच वरखाली होऊ शकतं. उदाहरणार्थ, 'आ' किती वेळा येईल याबद्दलचा वर दिलेला अंदाज भरवशाचा असतो, पण 'औ' बद्दल तसा तो करता येत नाही.
जोडाक्षरांचा उल्लेख करून हा विषय संपवतो. एकूण अक्षरांपैकी अंदाजे बारा टक्के अक्षरं ही जोडाक्षरं असतात. अर्थात इथे व्याख्येवरून वाद होऊ शकतो; उदाहरणार्थ, 'पंचवीस' या शब्दातलं 'ञ + च' हे जोडाक्षर मानलं तर हे प्रमाण साडेपंधरा टक्क्यापर्यंत चढतं. एकच एक जोडाक्षर नेहमी इतरांपेक्षा जास्त वेळा येतं अशी परिस्थिती दिसत नाही, पण बहुतकरून
च्य, त्य, त्र, प्र, ल्य
ही पाच खूपदा येतात; आणि त्यातसुद्धा पहिली दोन जास्त वेळा येतात. 'प्र' आला तर शब्दाच्या सुरवातीला पुष्कळदा येतो.
सर्वसाधारण चित्र उमटतं ते असं की मोजकीच आठदहा व्यंजनं आणि दोनतीन स्वर नेमून दिलेल्या प्रमाणात येणं आणि उरलेल्यांना तुलनेने फार कमी वाव राहणं हा मराठीचा (किंवा निदान लिखित मराठीचा) स्थायीभाव आहे. एकटादुकटा लेखक याबाबतीत फारसं काही करू शकत नाही, किंबहुना आपल्या लिखाणाखाली असा काही रचनाबंध आहे हे त्याला जाणवतसुद्धा नाही. रक्तातल्या लाल पेशींचं आणि पांढऱ्या पेशींचं परस्परप्रमाण तुमच्या आणि माझ्या शरीरात बहुतेक सारखंच असावं. पण तुम्ही आणि मी संगनमत करून हे प्रमाण ठरवलेलं नसतं. आणि ते सारखं असणं हे तुमच्याविषयी माझ्या मनात आत्मीयता निर्माण व्हायला फारसं सबळ कारणही नसतं.
मराठीत 'अ' आणि 'आ' हे दोन स्वर पुन्हापुन्हा येतात आणि त्यातदेखील 'अ' पुढे असतो, याची मला हा सगळा खटाटोप करण्याआधी पूर्वकल्पना होती. पाचेक वर्षांपूर्वी असा प्रयोग मी करून पाहिला होता की 'अ' हा स्वर न वापरता गोष्ट लिहावी. 'एका निनावी प्राण्याचा मृत्यू' ही त्यावेळी लिहिलेली गोष्ट इथे वाचता येईल.
हे झाल्यानंतरची साहजिक पुढची पायरी म्हणजे 'आ' हा स्वर टाळून काही लिहून पाहणं. भालचंद्र नेमाड्यांना लघुकथा आवडत नाहीत हे सर्वज्ञात आहे. त्यांनी 'टीकास्वयंवर' मध्ये कुठेतरी म्हटल्याप्रमाणे, 'ऊन मी म्हणत होतं' अशी काहीतरी सुरुवात करून मासिकं चालवण्यासाठी लिहिला जाणारा तो प्रकार आहे. अशा प्रकारे पहिलं वाक्य आयतं मिळाल्यामुळे माझा हुरूप वाढला, आणि 'घरोघरची मंडळी भरपेट जेवून अंमळ कलंडली होती' असं पुढचं वाक्यही तयार झालं, पण तरीदेखील ही कथा काही केल्या मला पुढे रेटता येईना. विशेषकरून 'आहे, नाही, आणि' हे शब्द वर्ज्य असल्यामुळे हालचाल करणं फार अवघड होऊन बसलं. सरतेशेवटी ही कथा जरी मला जमली नाही, तरीदेखील 'समष्टी व अभिव्यक्ती' या नावाने एक लहानसा वैचारिक लेख लिहिता आला. तो इथे वाचता येईल. 'अ' पेक्षा 'आ' कमी वेळा येतो याचा अर्थ असा नव्हे की 'अ' पेक्षा 'आ' टाळणं जास्त सोपं आहे.
श्रीपाद कृष्ण कोल्हटकरांच्या 'सुदाम्याचे पोहे' मधला एक प्रसंग असा की एका मराठी माणसाला कर्नाटकात जाण्याचा प्रसंग आला. त्याला कानडी येत नसल्यामुळे एका मडक्यात तो खडे भरून घेऊन गेला आणि जिथे जिथे बोलण्याचा प्रसंग येईल तिथे तिथे त्याने ते हलवून वाजवून दाखवलं. सगळ्यांना सगळं समजलं आणि त्याचं कुठे काही अडलं नाही.
एक अनुभव नेहमी येतो: मुळीच न समजणारी भाषा जर कानावर पडली तर ती कोणती आहे हे अनेकदा ओळखता येतं. स्वीडिश, फारसी आणि तामिळ कानाला फार वेगवेगळ्या लागतात. प्रत्येक भाषेत पुन्हापुन्हा येणारे काही विशिष्ट आवाज असतात आणि एखादा माणूस अपुऱ्या प्रकाशात त्याच्या चालीवरून ओळखता यावा तशी त्या आवाजांच्या आधारे भाषा ओळखता येते. पण याबाबतीत एक खेदाची गोष्ट अशी की भाषा जर समजत असेल तर तिचा अर्थ ऐकू आल्यामुळे आवाज ऐकू येईनासा होतो. यामुळे उदाहरणार्थ इटालियन भाषा इटालियन माणसं सोडून इतरांच्या कानाला गोड लागते.
वर जे स्टॅटिस्टिक्स शोधून काढलेलं आहे त्याचा आधार घेऊन मराठीचे आवाज तयार करण्याचा एक प्रयत्न मी करून पाहिला. यासाठी मी लिहिलेला कंप्यूटर प्रोग्रॅम काही नियमांना धरून रॅँडम नंबर जनरेटर वापरून शब्द तयार करतो. हे शब्द निरर्थक असतात, पण मराठीचं स्टॅटिस्टिक्स पाळणारे असतात. यासाठी मी बसवलेले नियम त्रोटकपणे खाली देतो आहे; त्यांच्यामागचा उद्देश असा की उंच टोपी घालून, तोंडात चिरूट ठेवून, येसफेस आवाज काढून जशी सुधारकांची थट्टा करत असत तशी मराठीत पुन्हापुन्हा येणारे आवाज काढून तिची थट्टा करायची.
१. फक्त त-र-य-क-ल-स-व-ह-च-न हीच दहा व्यंजनं वापरता येतील. रॅँडम नंबर जनरेटर फाशासारखा काम करतो. दहा बाजू असलेला फासा आहे आणि त्याच्या प्रत्येक बाजूवर एकेक व्यंजन लिहिलेलं आहेत अशी कल्पना करा. फासा टाकला की प्रत्येक वेळी दहापैकी कोणतंतरी एक व्यंजन निवडलं जाईल. पण फासा अोबडधोबड आहे आणि त्याच्या बाजू कमीजास्त आहेत असं समजा. यामुळे सगळ्या व्यंजनांना समान संधी नसेल. 'त' येण्याची शक्यता 'र' पेक्षा थोडी जास्त असेल. अर्थात या शक्यतांचं परस्परप्रमाण स्टॅटिस्टिक्सने शोधून काढल्याप्रमाणे बसवलेलं आहे.
२. या दहा व्यंजनांव्यतिरिक्त च्य-त्य-त्र-प्र-ल्य ही जोडाक्षरं चालतील; इतर कुठलीही नाहीत.
३. फक्त अ-आ-इ-ई-उ-ऊ-ए हेच स्वर वापरता येतील, त्यातदेखील शब्दाच्या सुरवातीला 'ई' किंवा शेवटी 'इ' येऊ शकणार नाही. व्यंजन + स्वर मिळून अक्षर होत असल्यामुळे स्वरदेखील वरच्यासारखा फासा टाकून निवडला जाईल.
४. स्वत:चं मराठीचं ज्ञान कुठेही वापरायचं नाही. उदाहरणार्थ, 'ला, चे' वगैरे प्रत्यय उठसूठ कुठल्याही शब्दाला लावणं हा मराठीची चेष्टा करण्याचा एक स्वस्त मार्ग आहे. तसं करायचं नाही.
हे नियम वापरून माझ्या लॅपटॉपवर मी एक छोटासा 'लेख' तयार करून पाहिला. त्याच्या वाचनाची माझ्या आवाजातली अॉडिओ फाईल लेखाच्या खाली दिलेली आहे. (प्रोग्रॅममध्ये रॅँडम जनरेशन अंतर्भूत असल्यामुळे तो पुन्हा चालवला तर पूर्णपणे वेगळा लेख बाहेर पडेल.) प्रयोग यशस्वी झाला आहे का याचा निवाडा ऐकणाऱ्यांवर सोपवतो असं मी प्रघातानुसार म्हणेनसुद्धा, पण खरी गोष्ट अशी की आपल्या सर्वांनाच मराठी येत असल्यामुळे या कामासाठी आपण तितकेसे लायक नाही. सुधारकाची नक्कल चांगली वठली आहे असा अभिप्राय आगरकरांनी कधी दिला नसणार.
हा विषय इथून पुढे कुठे नेता येईल? काही जुजबी कल्पना मांडतो.
१. इंग्रजीतलं सर्वांत प्रचलित अक्षर e हे जरी असलं तरी व्यंजन t हे आहे. इंग्रजीत t आणि मराठीत 'त' हा योगायोग आहे की दोन्ही भाषांचं मूळ एकच असल्याचा तो अवशिष्ट परिणाम आहे? इतर इंडो-युरोपियन भाषांमध्ये याबाबतीत साधर्म्य आहे का? हे सगळं शोधून काढता येईल.
२. अर्वाचीन लिखित मराठीचा एक ठराविक 'स्टॅटिस्टिकल प्रोफाईल' आहे असं आपण पाहिलं. पण चक्रधरकालीन किंवा तुकारामकालीन मराठीचा प्रोफाईल तोच असेल अशी मुळीच खात्री नाही. उदाहरणार्थ, तुकारामाच्या वेळी 'ळ' खूप वापरला जात असे ('तीळ जाळिले तांदूळ, काम क्रोध तैसेचि खळ…') पण मोरोपंत येईपर्यंत तो हळूहळू मागे पडत गेला, हे संभाव्य जरी नसलं तरी अशक्यही नाही. तेव्हा हा प्रोफाईल काळानुसार बदलत गेला का (की मराठीच्या इतिहासात तो कधीच फारसा बदललेला नाही) याची शहानिशा करता येईल. अर्थात हाच अभ्यास याच्या काटकोनी दिशेनेही करता येईल. उदाहरणार्थ, बंगाली आणि गुजराती आपल्या कानांना फार वेगवेगळ्या लागतात, याचाच अर्थ त्यांचा प्रोफाईल वेगळा असला पाहिजे. हा फरक कशात आहे याचा नुसता ऐकून अंदाज न करता डेटा मिळवून आणखी खोलात शिरता येईल.
३. नेहमी येणारा एक मुद्दा इथेही येतो. माझी सगळी सॅँपल्स ही इंटरनेटवरची असल्यामुळे बहुतकरून प्रमाण लिखित भाषेची आहेत. मराठीच्या इतर बोलीभाषांचे प्रोफाईल्स यापेक्षा वेगळे असणं शक्य आहे, किंवा खरंतर असावेतच. कोणीतरी ते शोधून काढायला हवेत.
४. वेगवेगळ्या व्यंजनांचा वापर खूप कमीजास्त असणं (म्हणजे 'त','र' झिजून गुळगुळीत झालेले आणि 'ग','ख' अजून लखलखीत, अशी परिस्थिती असणं) हा बुचकळ्यात टाकणारा प्रकार आहे. यामागच्या एका संभाव्य कारणाचा अंदाज थोडाफार करता येतो. उदाहरणार्थ, 'च' पेक्षा 'छ' म्हणायला जास्त कष्ट पडतात हे उघड आहे. तेव्हा चौदाव्या शतकातल्या कुठल्यातरी आळशी न्हाव्याने आपल्याकडे आलेल्या बामणाची छंपी करण्याऐवजी चंपी केली असेल, आणि बामणही भाषिक शुद्धतेचा फारसा भोक्ता नसल्यामुळे त्याने निमूटपणे मान तुकवली असेल हे शक्य आहे. असेच सरसकट बदल हजारो लोकांनी केल्यामुळे घाऊक प्रमाणात अनेक 'छ' चे 'च' आणि 'ख' चे 'क' इत्यादि झाले असावेत. पण इतकं कारण पुरेसं वाटत नाही. उदाहरणार्थ, 'त' वर्गाचा वापर 'च' वर्गाच्या अडीचपट असावा याची संगती यातून लागत नाही. ती शोधून काढायला हवी, पण 'माणसाच्या स्वरयंत्राची रचनाच तशी आहे' यापेक्षा नेमकं कारण देणं कदाचित इथे शक्यही नसेल.
करण्यासारखं पुष्कळ आहे.

प्रतिक्रिया
मजेशीर
मजेशीर आहे. त्या दोन गोष्टी फक्त हट्टामुळे जास्त आवडल्या.
हे रँडम मराठी वाचन मात्र संस्कृताळलेलं वाटतं. ते लोकांच्या लेखनामुळे का वाचनाच्या पद्धतीमुळे, हे माहीत नाही.
---
सांगोवांगीच्या गोष्टी म्हणजे विदा नव्हे.
+१ संस्कृत
कारण संस्कृतातही याच व्यंजनांचे बाहुल्य असावे.
मराठीत स्वरांची आणि व्यंजनांची शब्दाच्या सुरुवातीला वा अंती वा मध्ये वारंवारिता वेगळी असते. हा (अयादृच्छिक) तपशील रॅन्डम तुकड्यात गोवला नसावा, असे वाटते.
+२
शिवाय वाचताना 'श्व डिलिशन' नेहमीपेक्षा कमी वाटते आहे आणि त्यामुळे देखील संस्कृतचा भास होत असावा.
बाकी लेख मस्तच. आधी वाचलेली मूळ कल्पना आणि वाढवलेला भागही छान. माझ्या एका मित्राने हौस म्हणून इंग्रजीसाठी असे वर्ड-जेन आणि सेंट-जेनचे प्रोग्रॅम लिहिले होते ते आठवले. योगायोगाने तोही गणिताचाच विद्यार्थी आहे.
+२अ
"ध्वनिफितीत अवर्ण-निभृतीचा अभाव" मुद्दा महत्त्वाचा आहे. शब्दांतर्गत अवर्ण-निभृती फारच गुंतागुंतीची आहे, परंतु अन्त्य अकाराच्या निभृतीचे नियम तसे सोपे आहेत.
ध्वनिफितीत हे केले असते तर बरे झाले असते.
ध्वनिफितीकरिता जे स्वयंचलित लेखन केले, त्यात "शब्दाचा अंत" अथवा "सफेद जागा" हे चिन्हसुद्धा होते का?
मराठीत स्वरांची आणि
हेच लिहायला आलो होतो. त हे अक्षर अधिक प्रमाणात येण्याचं मुख्य कारण म्हणजे करतो, करतात, ही क्रियापदांची रूपं तसंंच तो, ती, ते ही सर्वनामं यांचा वारंवार होणारा वापर. तेव्हा त हे व्यंजन यादृच्छिकरीत्या वापरण्याऐवजी तात, तो, ते यांनी अंत होणारे शब्द वापरले आणि सर्वनामं वापरली तर कानाला ती अधिक मराठीसारखी वाटू शकेल. उदाहरणार्थ 'तरादत' या शब्दापेक्षा तेच स्वर-व्यंजनं वापरून केलेला 'दरतात' हा शब्द खूपच जास्त मराठी वाटतो. किंबहुना कुठचेच शब्द न घेता असे क्रमाक्रमाने अल्गोरिथम वापरून तयार होणारी वाक्यं बोली मराठीच्या किती जवळ जाऊ शकेल यातून भाषेविषयी बरंच काही शिकता येईल.
उद्देश?
या खेळाचा उद्देश नेमका काय आहे? एक तोंडाने वदलेला निरर्थक परिच्छेद (मराठी न समजणार्या) कानांना मराठीसदृश भासविणे, की एक देवनागरीत लिहिलेला निरर्थक परिच्छेद (मराठी न समजणार्या, परंतु देवनागरी वाचता येणार्या) डोळ्यांना मराठीसदृश भासविणे?
याव्यतिरिक्त, काही रेघोट्या ओढून (देवनागरी वाचता न येणार्या) डोळ्यांना त्या देवनागरीसमान भासविता येतील काय? त्याकरिता काय(काय) करावे लागेल? (फक्त शिरोरेषा उपयोगाची नाही. म्हणजे, ती पाहिजेच; परंतु ती इतरही काही लिप्यांत असावी बहुधा.)
...
त्यापेक्षासुद्धा, आम्हांस तो मडक्यात दगडवाला इफेक्ट जाणवला.
(किंवा, हे मराठी असलेच कदाचित, तर 'श्री चामुण्डराजे करवीयले' छापाचे असू शकेल. चूभूद्याघ्या.)
(बाकी, केवळ अमूक स्वर इतके टक्के नि अमूक व्यंजने इतके टक्के, एवढे पुरेसे नसावे कदाचित. स्वरांव्यंजनांचा, झालेच तर र्हस्वदीर्घांचा प्याटर्नसुद्धा महत्त्व राखत असावा बहुधा.)
(कदाचित, एखादे रेग्युलर मराठी वाक्य घेऊन त्यातले स्वर तसेच ठेवून त्यातली व्यंजने तेवढी र्याण्डमली बदलली, तर?)
मनोरंजक
मनोरंजक कार्य आहे.
माझ्याजवळील मोल्सवर्थच्या १८५७ च्या पीडीएफ आवृत्तीमध्ये प्रस्तावना, पुरवणीसह एकूण ९६१ पाने आहेत. त्यातून मला इच्छित शब्दापर्यंत लगेच पोहोचता यावे म्ह्णून कोठले अ़क्षर कोठे सुरू होते असा एक तक्ता मी माझ्यापुरता तयार केला आहे. त्यावरून शब्दांचे पहिले अक्षर असण्याचा क्रम लावता येतो. सँपल पुरेसे मोठे आहे तसेच शब्दांच्या व्याख्या करण्यात कोठलाहि बायस नाही असे मानून पाहिले तर पहिले अक्षर असण्याच्या पृष्ठांच्या संख्या अशा आहेत:
स - ७५, क - ६७, प - ६६, अ - ५८, व - ५३, ब - ३९, श - ३६, ग - ३३, च - ३२, द - ३२, त - ३१. (उरलेली अक्षरे ३० च्या खाली आहेत.) स्वरवर्ग - १२२, कवर्ग - १४३, चवर्ग - ७८, टवर्ग - २७, तवर्ग - ११७, पवर्ग - १९४, य पासून पुढे २४१.
चिपलकट्टींना सापडले त्याच्या विरुद्ध येथे दिसत आहे. पहिले अक्षर असा निष्कर्ष लावला तर 'त' चा क्रमांक महत्त्वाच्या अक्षरांमध्ये शेवटचा आहे. असे का व्हावे? 'त' हे अक्षर जर सर्वात अधिक वापराचे आहे तर 'त'ने सुरू होणारे शब्द इतके कमी का?
चिपलकट्टींनी केल्याप्रमाणेच विशिष्ट अक्षरांचा वापर किती आहे हे मोजून रामायणामध्ये किती रचनाकारांनी कोणत्या पुरवण्या घातल्या आहेत असे संशोधन एम.आर.यार्दी ह्यांनी केले आहे. त्याची येथे आठवण येते.
रोचक मुद्दा
रोचक मुद्दा आहे. पटकन उत्तर सुचतं ते इतकंच की शब्दाच्या सुरवातीला वापरली जाणारी व्यंजनं काही कारणाने वेगळी (atypical) असावीत. उदाहरणार्थ, इंग्रजीत सर्वाधिक वापरली जाणारी पहिली तीन व्यंजनं उतरत्या भांजणीने t-n-s अशी आहेत. पण माझ्या इंग्रजी-जर्मन डिक्शनरीतली ती पानं मोजली तर ४७-१४-९८ इतकी आहेत.
- जयदीप चिपलकट्टी
(होमपेज)
त-आख्यात आणि प्रत्यय
क्रियापदाचे त-आख्यात (मी कर'तो'), आणि तकारप्रत्ययांमुळे मराठीतले तवर्ण शब्दात आदिवेगळ्या स्थानात मोठ्या प्रमाणात सापडतील.
ज.चि., युनिकोड धारिण्यांमध्ये ज्ञानेश्वरी आणि दासबोध उपलब्ध आहेत.
+१
शिवाय हा त-प्रत्यय संस्कृतातही आहेच. संस्कृतोद्भवांपैकी मराठी अन हिंदीतही आहे. बंगालीत नाही.
माहिष्मती साम्राज्यं अस्माकं अजेयं
उपयोजन
भाषेचं हे असं विश्लेषण वगैरे प्रकार भन्नाट आहेच.
पण ह्या विश्लेषणाचं उपयोजन नेमकं कुठं कुठं करता येइल असा मी विचार करतोय.
उदा :- ग्रंथांमधील प्रक्षिप्त भाग ओळखणे वगैरे परिचित गोष्टी आहेतच. किंवा
संरक्षण्/हेर खात्यासाठी मुद्दाम काही सांकेतिक भाषा/लिपी बनवणे (वर दिलेल्या शेरलॉक होम्स स्टाइल)
किंवा आहे त्याच भाषेचं छपाई/टंकन ह्या दृष्टीनं सुलभीकरण करता येइल.
अजून काय काय उपयोग होत असेल ?
(उपयोग असलाच पाहिजे असा आग्रह नाही; नुसते विश्लेषण करण्यातही मजा/आनंद असू शकतो; हे मान्य.
पण ही गरज कुठून निर्माण झाली असावी ह्याचा विचार करतोय.)
--मनोबा
.
संगति जयाच्या खेळलो मी सदाहि | हाकेस तो आता ओ देत नाही
.
memories....often the marks people leave are scars
भाषा आजची?
लेख निवडताना ते बर्यापैकी प्रमाण आणि ब्राह्मणाळलेल्या मराठीत असलेलेच निवडले होते का? बोली भाषेतलं खूप संवाद असलेलं ललित लिखाण घेतलं, किंवा अग्रलेख वगैरे वगळून फक्त म.टा.च्या तिखट तरुणाई भाषेतल्या पुरवण्यांमधल्या चटपटीत लेखांसारखं निवडलं, तर काय फरक पडेल असा प्रश्न पडला. म्हणजे संस्कृताळलेली भाषा न वापरणारं लिखाण असलं तर काय होईल?
- चिंतातुर जंतू
"ही जीवांची इतकी गरदी जगात आहे का रास्त |
भरती मूर्खांचीच होत ना?" "एक तूच होसी ज्यास्त" ||
हो आणि नाही
लेख प्रमाण मराठीतले आहेत (हे वर मुद्दा क्र. ३ मध्ये नमूद केलेलं आहे), पण संस्कृताळलेलेच आहेत असं नाही. उदाहरणार्थ, शहराजाद यांच्या लेखामधली (सॅँपल क्र. ३८) काही वाक्यं:
सगळे आपला फायदा घ्यायला टपले आहेत असाच कायम आविर्भाव. वास्तविक ह्या मुली तश्या बाहेरचं जग पाहिलेल्या. त्या काळातही अगदी नऊवारी लुगड्यात कॉलेजात जाऊन त्यांनी पदव्याही घेतलेल्या होत्या. पण कॉलेजातून घरी आल्यावर घरात बंद. काही माणसे आपली कोणाच्या अध्यात ना मध्यात, आपण बरे की आपले काम बरे, अशी असतात. पण ह्यांची तर्हा त्यापलीकडची होती.
यात संस्कृत शब्द तुरळकच आले आहेत. उलट 'कॉलेज' हा लॅटिनाळलेला शब्द दोनदा आला आहे, आणि 'फायदा', 'कायम', असे म्लेंच्छ शब्दही आहेत. (शहराजाद यांचा ID सुद्धा अगदीच असंस्कृत आहे.) पण ते काही असलं तरी अप्रमाण भाषांचा असा अभ्यास व्हायला हवा हा मुद्दा मला मान्यच आहे, आणि तोही वर क्र. ३ मध्ये आलेला आहे.
- जयदीप चिपलकट्टी
(होमपेज)
रोचक प्रयोग आहे.मलादेखील
रोचक प्रयोग आहे.
मलादेखील मनोबासारखाच प्रश्न पडला.
'एका निनावी प्राण्याचा मृत्यू' आवडली.
आणि आवाज चांगला आहे चिपलकट्टींचा. पण रेकॉर्डींग क्लिअर नाही.
+१
रोचक प्रयोग आहे.
जे वाचले ते लिहिले.
प्रभावी लोकं जे शब्द अधिक वापरतात ते त्या वर्तुळात अधिक वापरलं जाणं शक्य आहे. उदा. इथे चिंतातुर जंतूंमुळे 'रोचक' हा शब्द अधिक वापरला जातो. अधिक लिहिणार्याची शब्दसंपदा(वाचन) कमी असल्यास तुमच्या सँपलसेट मधल्या लेखनात तेच शब्द/व्यंजंन/अक्षरं/जोडाक्षरं अधिक आढळणे शक्य आहे काय?
त र
हे खरं आहे का ते सांगता येणार नाही; पण मी आता 'गंमतीशीर'चा पर्याय दिला आहे. त्यात 'त'सुद्धा आहे आणि 'र'सुद्धा.
- चिंतातुर जंतू
"ही जीवांची इतकी गरदी जगात आहे का रास्त |
भरती मूर्खांचीच होत ना?" "एक तूच होसी ज्यास्त" ||
उरले फक्त उपकरांपु'रते'
अहो एंव्हढेंच ते काय, तुमच्या नावातही 'त-र' आहे.
त-र च्या निमित्ताने हा फेमस
त-र च्या निमित्ताने हा फेमस संस्कृत श्लोक आठवला.
तारतारतरैरेतैरुत्तरोत्तरतो रुतैः ।
रतार्त्ता तित्तिरी रौति तीरे तीरे तरौ तरौ ॥
याच्या भाषांतराबद्दल खालील दुवा रोचक ठरावा.
http://www.rasalabooks.com/sound-play/
माहिष्मती साम्राज्यं अस्माकं अजेयं
वा!!! क्लास असा श्लोक आहे हेच
वा!!! क्लास असा श्लोक आहे हेच माहीत नव्हते. बॅट्यामुळे संस्कृत जीवंत रहाणार
दंडवत!
__/\__
दंडवत. चिकाटीला, कल्पनेला आणि त्याबद्दलच्या सोप्या लेखनालाही!
माझा (वा माझ्याइतकं अशुद्धलेखन असलेला) लेख घेतला असतात तर उत्तरे वेगळी संभवत असती काय?
- ऋ
-------
लव्ह अॅड लेट लव्ह!
कल्पना व विश्लेषण आवडले
खूप वेगळी माहिती मिळाली. धन्यवाद
- स्वधर्म
प्रतिप्रतिक्रिया
प्रतिक्रिया देणाऱ्या सर्वांचे मनापासून आभार. त्यातल्या काही प्रतिक्रियांना मोघम उत्तरं देतो आहे:
राघा: करतात, येते इत्यादिच्या शेवटी 'त' खूपदा येतो, किंवा तो-ती-ते या सर्वनामांत येतो याबद्दल शंकाच नाही. पण प्रोग्रॅममध्ये याचा अंतर्भाव केलेला नाही, कारण मी स्वत:वरच घालून घेतलेल्या बंधनानुसार ते 'चीटिंग' झालं असतं. स्वत:ला मुळीच मराठी येत नाही आणि व्याकरणाची काहीही माहिती नाही, फक्त लेटर फ्रिक्वेन्सीस माहिती आहेत असं समजून प्रोग्रॅम लिहायचं ठरवलं होतं.
मिहिर + धनंजय: schwa deletion चा मुद्दा कळीचा आहे, आणि वाचन करत असताना मला तो अंधुकसा जाणवला होताच. पण मजकूर जर पूर्ण निरर्थक असेल तर डिलीशन कुठे करायचं याचा निर्णय अवघड होतो, निदान मला तरी तो तसा वाटला. (आणि म्हणूनच ते फारसं केलेलं नाही.) सध्या 'शब्दाचा अंत' ही खूण प्रोग्रॅममध्ये अंतर्भूत आहे, पण ती घालायला हवी होती का याबद्दल मलाच शंका आहेत. कारण जर फार अपरिचित असलेली भाषा ऐकली (स्वीडिश, टर्किश वगैरे) तर ती कळत नाही इतकंच नव्हे तर शब्द कुठे तुटतात हेही नक्की सांगता येत नाही.
पण असो. मी प्रोग्रॅम लिहिलेला आहे तो संगणकामध्ये, काळ्या दगडावर नव्हे. त्यात इथेतिथे फेरफार करून वेगळं काही निघतं का हे मी पाहीनच, आणि मग तसतशी या धाग्यात भरही टाकत राहता येईल. आणि दुसऱ्या कुणी वेगळ्या दिशेने अशासारखा प्रयोग करून पाहिला तर आणखी उत्तम. एकाच गोष्टीची थट्टा अनेक प्रकारे करता येते.
- जयदीप चिपलकट्टी
(होमपेज)
शब्दाचा अंत, वाचताना आघात
शब्दाचा अंत म्हणजे ध्वनिरोध नसतो, हे तुमचे म्हणणे अगदी बरोबरच आहे. परंतु अनेक भाषांत (मराठीतही) प्रत्येक शब्दात एक प्रमुख आघात असतो. मराठीत साधारणपणे पहिले अक्षर, नाहीतर जोडाक्षराआदले अक्षर... वगैरे.
असे आघात पाठ्य वाचताना सारखेसारखे आले नाहीत, तर वाचन मराठीसारखे भासणार नाही. यादृच्छिक पाठ्यात शब्दांतचिन्ह हे "यापुढे आघात देणे" असे चिन्ह आहे. (ध्वनी खंडित होऊ देणे, असे नाही.)
शब्दादि व्यंजनांची मोजदाद
वरील लेखातच बघा ना, कुठली व्यंजने कितपत शब्दादिस्थानावर येतात, त्यात मोठाच फरक दिसू शकतो :
(शब्दादि = "[सफेद जागा]व्यंजन" असे मोजले. यात परिच्छेदातला पहिला शब्द हुकला. परंतु त्याने पुढील टक्केवारी थोडीच बदलावी.)
<२०% शब्दादि सापडणारी व्यंजने लाल ठशात, >३०% शब्दादि सापडणारी व्यंजने जांभळ्या-निळ्या ठशात
व्यंजन : शब्दादि/सर्वसंख्या (टक्के%)
त : १४१/४५९ (२६%)
र : १६/५४३ (३%)
य : ९८/४२७ (२३%)
क : १६२/४२३ (३८%)
ल : ६८/३९९ (१७%)
स : १०६/३४७ (३१%)
ह : ९८/३२६ (३०%)
न : ९२/३१२ (२९%)
व : १०५/२८७ (३७%)
च : २९/२३८ (१२%)
प : १२३/२३७ (५२%)
म : १०८/२३४ (४६%)
ण : ०/१९८ (०%)
ज : ४८/१२८ (३८%)
द : ३६/१२८ (२८%)
ग : २२/१२८ (१९%)
ळ : ०/११३ (०%)
श : ४४/१०० (४४%)
(सगळी मिळून ५३९४ व्यंजनचिन्हे आहेत. वर दिल्यावेगळी अन्य व्यंजने १००पेक्षा कमी आहेत, त्यामुळे ती टंकत नाही.)
म्हणजे कुठली व्यंजने शब्दादि येतात त्यांच्यात खूपच कमीअधिक दिसते. "र" किती कमी प्रमाणात शब्दादि दिसते, ते पाहून मला फारच आश्चर्य वाटते आहे. प, म वगैरे अर्ध्या वेळा शब्दादि दिसतात. ण, ळ शब्दादि दिसत नाहीत ते तर सर्वांना ठाऊकच आहे, पण येथे ते तक्त्यातही दिसते.
"ल" हे ("त"पेक्षा) कमी प्रमाणात शब्दादि दिसते. इतकेच काय शब्दान्तीचे ला-ली-ले-लो असे १११ प्रयोग आहेत - त्यामुळे या प्रत्ययांचे बाहुल्य (२८%) शब्दादिपेक्षा (१७%) मराठीत पुष्कळ जाणवणार.
शब्दान्तीचे ता-ती-तो-ते (यात तो, ती आणि ते ही सर्वनामे वगळली) हे १८७ वेळा आलेत, म्हणजे ३४%, शब्दादिप्रयोगापेक्षा जास्तच - पुन्हा प्रत्ययांमुळे हे बाहुल्य.
(शब्दांतीच्या अक्षरातले व्यंजन मोजायला मला जरा जास्तच वेळ लागला, म्हणून "च" घेतला नाही.)
ज.चि. म्हणतात -
> स्वत:चं मराठीचं ज्ञान कुठेही वापरायचं नाही. उदाहरणार्थ, 'ला, चे' वगैरे प्रत्यय उठसूठ कुठल्याही
> शब्दाला लावणं हा मराठीची चेष्टा करण्याचा एक स्वस्त मार्ग आहे. तसं करायचं नाही.
परंतु असा नियम घालून दिल्यामुळे त्यांचे यादृच्छिक पाठ्य मुद्दामून मराठीपेक्षा दूर जाते. असे न करता, त्यांनी पहिल्या (वाटल्यास मधल्या) शेवटल्या व्यंजनांची आणि स्वरांची वारंवारिता वेगळी मोजावी, आणि अशा प्रकारे यादृच्छिक शब्द तयार करावेत. शब्दांती र्हस्व इ/उ व्यंजनाची वारंवारिता ० ठेवावी. शब्दांतीचा "अ" उच्चारताना लुप्त करावा. मग हे यादृच्छिक पाठ्य काहीसे मराठीसारखे ऐकू येईल.
मस्त
लेखाबरोबरच कथा आणि प्रोग्रामींगचे प्रयोग आवडले
व्हिटनीच्या गणनेनुसार संस्कृतमध्ये अ आ त र व इ न म य स ही अक्षरं सर्वात जास्त वापरली गेली आहेत.
मराठीत म नाही हे पाहून आश्चर्य वाटलं.